

Understanding the node state model
This article describes the node state model that is the core design
abstraction inside the oak-core component. Understanding the node state
model is essential to working with Oak internals and to building custom
Oak extensions.
Background
Oak organizes all content in a large tree hierarchy that consists of nodes and properties. Each snapshot or revision of this content tree is immutable, and changes to the tree are expressed as a sequence of new revisions. The NodeStore of an Oak repository is responsible for managing the content tree and its revisions.
The node state model as expressed in the NodeState interface in oak-core is designed for these purposes. It provides a unified low-level abstraction for managing all tree content and lays the foundation for the higher-level Oak API that's visible to clients.
The state of a node
A node in Oak is an unordered collection of named properties and child nodes. As the content tree evolves through a sequence of revisions, a node in it will go through a series of different states. A node state then is an immutable snapshot of a specific state of a node and the subtree beneath it.
As an example, the following diagram shows two revisions of a content tree, the first revision consists of five nodes, and in the second revision a sixth node is added in one of the subtrees. Note how unmodified subtrees can be shared across revisions, while only the modified nodes and their ancestors up to the root (shown in yellow) need to be updated to reflect the change. This way both revisions remain readable at all times without the implementation having to make a separate copy of the entire repository for each revision.
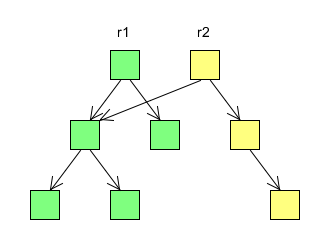
To avoid making a special case of the root node and therefore to make it easy to write algorithms that can recursively process each subtree as a standalone content tree, a node state is unnamed and does not contain information about it's location within a larger content tree. Instead each property and child node state is uniquely named within a parent node state. An algorithm that needs to know the path of a node can construct it from the encountered names as it descends the tree structure.
Since node states are immutable, they are also easy to keep thread-safe. Implementations that use mutable data structures like caches or otherwise aren't thread-safe by default, are expected to use other mechanisms like synchronization to ensure thread-safety.
The NodeState interface
The above design principles are reflected in the NodeState interface
in the org.apache.jackrabbit.oak.spi.state package of oak-core. The
interface consists of three sets of methods:
- Methods for accessing properties
- Methods for accessing child nodes
- The
existsmethod for checking whether the node exists or is accessible - The
buildermethod for building modified states - The
compareAgainstBaseStatemethod for comparing states
You can request a property or a child node by name, get the number of properties or child nodes, or iterate through all of them. Even though properties and child nodes are accessed through separate methods, they share the same namespace so a given name can either refer to a property or a child node, but not to both at the same time.
Iteration order of properties and child nodes is unspecified but stable, so that re-iterating through the items of a specific NodeState instance will return the items in the same order as before, but the specific ordering is not defined nor does it necessarily remain the same across different instances.
The last three methods, exists, builder and compareAgainstBaseState,
are covered in the next sections. See also the NodeState javadocs for
more details about this interface and all its methods.
Existence and iterability of node states
The exists method makes it possible to always traverse any path regardless
of whether the named content exists or not. The getChildNode method returns
a child NodeState instance for any given name, and the caller is expected
to use the exists method to check whether the named node actually does exist.
The purpose of this feature is to allow paths like /foo/bar to be traversed
even if the current user only has read access to the bar node but not its
parent foo. As a consequence it's even possible to access content like a
fictional /bar subtree that doesn't exist at all. A piece of code for
accessing such content could look like this:
NodeState root = ...;
NodeState foo = root.getChildNode("foo");
assert !foo.exists();
NodeState bar = foo.getChildNode("bar");
assert bar.exists();
NodeState baz = root.getChildNode("baz");
assert !baz.exists();
The following diagram illustrates such a content tree, both as the raw content that simply exists and as an access controlled view of that tree:
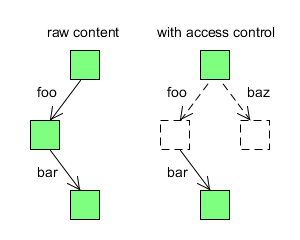
If a node is missing, i.e. its exists method returns false and thus it
either does not exist at all or is read-protected, one can't list any of
its properties or child nodes. And on the other hand, a non-readable node or
property will only show up when listing the child nodes or properties of its
parent. In other words, a node or a property is iterable only if both it
and its parent are readable. For example, attempts to list properties or
child nodes of the node foo will show up empty:
assert !foo.getProperties().iterator().hasNext();
assert !foo.getChildNodeEntries().iterator().hasNext();
Note that without some external knowledge about the accessibility of a child
node like bar there's no way for a piece of code to distinguish between
the existing but non-readable node foo and the non-existing node baz.
Building new node states
Since node states are immutable, a separate builder interface,
NodeBuilder, is used to construct new, modified node states. Calling
the builder method on a node state returns such a builder for
modifying that node and the subtree below it.
A node builder can be thought of as a mutable version of a node state.
In addition to property and child node access methods like the ones that
are already present in the NodeState interface, the NodeBuilder
interface contains the following key methods:
- The
setPropertyandremovePropertymethods for modifying properties - The
getChildNodemethod for accessing or modifying an existing subtree - The
setChildNodeandremoveChildNodemethods for adding, replacing or removing a subtree - The
existsmethod for checking whether the node represented by a builder exists or is accessible - The
getNodeStatemethod for getting a frozen snapshot of the modified content tree
All the builders acquired from the same root builder instance are linked so that changes made through one instance automatically become visible in the other builders. For example:
NodeBuilder rootBuilder = root.builder();
NodeBuilder fooBuilder = rootBuilder.getChildNode("foo");
NodeBuilder barBuilder = fooBuilder.getChildNode("bar");
assert !barBuilder.getBoolean("x");
fooBuilder.getNodeChild("bar").setProperty("x", Boolean.TRUE);
assert barBuilder.getBoolean("x");
assert barBuilder.exists();
fooBuilder.removeChildNode("bar");
assert !barBuilder.exists();
The getNodeState method returns a frozen, immutable snapshot of the current
state of the builder. Providing such a snapshot can be somewhat expensive
especially if there are many changes in the builder, so the method should
generally only be used as the last step after all intended changes have
been made. Meanwhile the accessors in the NodeBuilder interface can be
used to provide efficient read access to the current state of the tree
being modified.
The node states constructed by a builder often retain an internal reference to the base state used by the builder. This allows common node state comparisons to perform really well as described in the next section.
Comparing node states
As a node evolves through a sequence of states, it's often important to
be able to tell what has changed between two states of the node. This
functionality is available through the compareAgainstBaseState method.
The method takes two arguments:
- A base state for the comparison. The comparison will report all changes necessary for moving from the given base state to the node state on which the comparison method is invoked.
- A
NodeStateDiffinstance to which all detected changes are reported. The diff interface contains callback methods for reporting added, modified or removed properties or child nodes.
The comparison method can actually be used to compare any two nodes, but the
implementations of the method are typically heavily optimized for the case
when the given base state actually is an earlier version of the same node.
In practice this is by far the most common scenario for node state comparisons,
and can typically be executed in O(d) time where d is the number of
changes between the two states. The fallback strategy for comparing two
completely unrelated node states can be much more expensive.
An important detail of the NodeStateDiff mechanism is the childNodeChanged
method that will get called if there can be any changes in the subtree
starting at the named child node. The comparison method should thus be able
to efficiently detect differences at any depth below the given nodes. On the
other hand the childNodeChanged method is called only for the direct child
node, and the diff implementation should explicitly recurse down the tree
if it wants to know what exactly did change under that subtree. The code
for such recursion typically looks something like this:
public void childNodeChanged(
String name, NodeState before, NodeState after) {
after.compareAgainstBaseState(before, ...);
}
Note that for performance reasons it's possible for the childNodeChanged
method to be called in some cases even if there actually are no changes
within that subtree. The only hard guarantee is that if that method is not
called for a subtree, then that subtree definitely has not changed, but in
most common cases the compareAgainstBaseState implementation can detect
such cases and thus avoid extra childNodeChanged calls. However it's
important that diff handlers are prepared to deal with such events.
The commit hook mechanism
A repository typically has various constraints to control what kind of content is allowed. It often also wants to annotate content changes with additional modifications like adding auto-created content or updating in-content indices. The commit hook mechanism is designed for these purposes. An Oak instance has a list of commit hooks that it applies to all commits. A commit hook is in full control of what to do with the commit: it can reject the commit, pass it through as-is, or modify it in any way.
All commit hooks implement the CommitHook interface that contains just
a single processCommit method:
NodeState processCommit(NodeState before, NodeState after)
throws CommitFailedException;
The before state is the original revision on which the content changes
being committed are based, and the after state contains all those changes.
A after.compareAgainstBaseState(before, ...) call can be used to find out
the exact set of changes being committed.
If, based on the content diff or some other inspection of the commit, a
hook decides to reject the commit for example due to a constraint violation,
it can do so by throwing a CommitFailedException with an appropriate error
code as outlined in https://jackrabbit.apache.org/archive/wiki/JCR/OakErrorCodes_115513474.html.
If the commit is acceptable, the hook can return the after state as-is or it can make some additional modifications and return the resulting node state. The returned state is then passed as the after state to the next hook until all the hooks have had a chance to process the commit. The resulting final node state is then persisted as a new revision and made available to other Oak clients.
Commit editors
In practice most commit hooks are interested in the content diff as returned
by the compareAgainstBaseState call mentioned above. This call can be
somewhat expensive especially for large commits, so it's not a good idea for
multiple commit hooks to each do a separate diff. A more efficient approach
is to do the diff just once and have multiple hooks process it in parallel.
The commit editor mechanism is used for this purpose. An editor is
essentially a commit hook optimized for processing content diffs.
Instead of a list of separate hooks, the editors are all handled by a single
EditorHook instance. This hook handles the details of performing the
content diff and notifying all available editors about the detected content
changes. The editors are provided by a list of EditorProvider instances
that implement the following method:
Editor getRootEditor(
NodeState before, NodeState after, NodeBuilder builder)
throws CommitFailedException;
Instead of comparing the given before and after states directly, the provider
is expected to return an Editor instance to be used for the comparison.
The before and after states are passed to this method so that the provider
can collect generic information like node type definitions that is needed
to construct the returned editor.
The given NodeBuilder instance can be used by the returned editor to make
modifications based on the detected content changes. The builder is based
on the after state, but it is shared by multiple editors so during the diff
processing it might no longer exactly match the after state. Editors within
a single editor hook should generally not attempt to make conflicting changes.
The Editor interface is much like the NodeStateDiff interface described
earlier. The main differences are that all the editor methods are allowed to
throw CommitFailedExceptions and that the child node modification methods
all return a further Editor instance.
The idea is that each editor instance is normally used for observing the changes to just a single node. When there are changes to a subtree below that node, the relevant child node modification method is expected to return a new editor instance for observing changes in that subtree. The editor hook keeps track of these returned “sub-editors” and recursively notifies them of changes in the relevant subtrees.
If an editor is not interested in changes inside a particular subtree it can
return null to notify the editor hook that there's no need to recurse down
that subtree. And if the effect of an editor isn't tied to the location of
the changes within the content tree, it can just return itself. A good example
is a name validator that simply checks the validity of all names regardless
of where they're stored. If the location is relevant, for example when you
need to keep track of the path of the changed node, you can store that
information as internal state of the returned editor instance.
Commit validators
As mentioned, a common use for commit hooks is to verify that all content changes preserve the applicable constraints. For example the repository may want to enforce the integrity of reference properties, the constraints defined in node types, or simply the well-formedness of the names used. Such validation is typically based on the content diff of a commit, so the editor mechanism is a natural match. Additionally, since validation doesn't imply any further content modifications, the editor mechanism can be further restricted for this particular case.
The abstract ValidatorProvider class and the related Validator interface
are based on the respective editor interfaces. The main difference is that
the validator provider drops the NodeBuilder argument to make it impossible
for any validators to even accidentally modify the commit being processed.
Thus, even though there's no performance benefit to using the Validator
interface instead of Editor, it's a good idea to do so whenever possible
to make the intention of your code clearer.