

Lucene Index
- New in 1.6
- Index Definition
- Near Real Time Indexing
- LuceneIndexProvider Configuration
- Tika Config
- Non Root Index Definitions
- Function-Based Indexing
- Dynamic Boost
- Native Query and Index Selection
- Persisting indexes
- CopyOnRead
- CopyOnWrite
- Lucene Index MBeans
- Active Index Files Collection
- Analyzing created Lucene Index
- Pre-Extracting Text from Binaries
- Advanced search features
- Design Considerations
- Limits
- Lucene Index vs Property Index
- Examples
Oak supports Lucene based indexes to support both property constraint and full text constraints. Depending on the configuration a Lucene index can be used to evaluate property constraints, full text constraints, path restrictions and sorting.
SELECT * FROM [nt:base] WHERE [assetType] = 'image'
Following index definition would allow using Lucene index for above query
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- type = "lucene"
- compatVersion = 2
- async = "async"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ assetType
- propertyIndex = true
- name = "assetType"
The index definition node for a lucene-based index
- must be of type
oak:QueryIndexDefinition - must have the
typeproperty set tolucene - must contain the
asyncproperty set to the valueasync, this is what sends the index update process to a background thread
Note that compared to Property Index Lucene Property Index is always configured in Async mode hence it might lag behind in reflecting the current repository state while performing the query
Taking another example. To support the following query
/jcr:root/content//*[jcr:contains(., 'text')]
The Lucene index needs to be configured to index all properties
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- type = "lucene"
- compatVersion = 2
- async = "async"
- includedPaths = ["/content"]
- queryPaths = ["/content"]
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ allProps
- name = ".*"
- isRegexp = true
- nodeScopeIndex = true
New in 1.6
Following are the new features in 1.6 release
Index Definition
Lucene index definition consist of indexingRules, analyzers ,
aggregates etc which determine which node and properties are to be indexed
and how they are indexed.
Below is the canonical index definition structure
luceneIndex (oak:QueryIndexDefinition)
- type (string) = 'lucene' mandatory
- async (string) = 'async' mandatory
- codec (string)
- compatVersion (long) = 2
- evaluatePathRestrictions (boolean) = false
- valueRegex (string)
- queryFilterRegex (string)
- includedPaths (string) multiple
- queryPaths (string) multiple = ['/']
- excludedPaths (string) multiple
- maxFieldLength (long) = 10000
- maxTagLength (long) = 100
- maxSimilarityTagsCount (long) = 50
- maxDynamicBoostCount (long) = 50
- refresh (boolean)
- useIfExists (string)
- blobSize (long) = 32768
- functionName (string)
- name (string)
- indexPath (string)
+ indexRules (nt:unstructured)
+ aggregates (nt:unstructured)
+ analyzers (nt:unstructured)
+ tika (nt:unstructured)
Following are the config options which can be defined at the index definition level
- type
- Required and should always be
lucene. - async
- Required and should always be
async, or [async,nrt]. - codec
- Optional string property.
- Name of the Lucene codec to use
- compatVersion
- Required integer property, needs to be set to 2
- Version 1 is deprecated, and new indexes should always use version 2. Version 1 doesn't support property restrictions and index time aggregation. A compatVersion 2 full text index is usually faster to run queries. For full text indexing with compatVersion 2, at query time, only the access right of the parent (aggregate) node is checked, and the access right of the child nodes is not checked. If this is a concern, then aggregation should not be used.
- evaluatePathRestrictions
- Optional boolean property defaults to
false. - If enabled the index can evaluate path restrictions
- valueRegex
- Optional string property
- A regular expression for property value in index definition. If this is specified, then only those properties would be added to index whose value matches the regex defined by this property.
- queryFilterRegex
- Optional string property
- A regular expression for query text. If this property is present in an index definition, then those queries whose search text doesn't match this pattern but are still using the index will log a warning. If this property is not specified, but valueRegex is specified, that property is also used for the use case specified here.
- includedPaths
- Optional multi value property. Defaults to ‘/’.
- List of paths which should be included in the index. If used, ‘queryPaths’ should be set to the same value(s). See Path Includes/Excludes for details.
- queryPaths
- Optional multi value property. Defaults to ‘/’.
- List of paths for which the index can be used to perform queries. If used, ‘includedPaths’ should be set to the same value(s). See Path Includes/Excludes for details.
- excludedPaths
- Optional multi value property. Defaults to empty.
- List of paths which should be excluded from indexing. See Path Includes/Excludes for details.
- tags
- Optional multi value property. Defaults to empty.
- List of tags of this index.
- selectionPolicy
- Optional string property. Defaults to empty.
- The selection policy of this index.
- maxFieldLength
- Numbers of terms indexed per field. Defaults to 10000
- maxTagLength
- Optional integer property. Defaults to 100.
- Maximum length of similarity tag and dynamic boost tag values to be indexed. Tags with values longer than this limit are skipped during indexing. Set to -1 to disable the length check entirely. See Dynamic Boost and Search by similar feature vectors for details.
- maxSimilarityTagsCount
- Optional integer property. Defaults to 50.
- Maximum number of similarity tags to index per document. When the limit is exceeded, only the first N tags (in order of appearance) are indexed and subsequent tags are skipped. Set to -1 to disable the limit entirely. See Search by similar feature vectors for details.
- maxDynamicBoostCount
- Optional integer property. Defaults to 50.
- Maximum number of dynamic boost tags to index per document. When the limit is exceeded, tags are sorted by confidence (descending) and only the top N are indexed. Set to -1 to disable the limit entirely. See Dynamic Boost for details.
- refresh
- Optional boolean property.
- Used to refresh the stored index definition. See Effective Index Definition
- useIfExists
- Optional string property
- Only use this index for queries if the given node or property exists.
This is specially useful in blue-green deployments, when using the composite node store.
For example, if set to
/libs/indexes/acme/@v1, the index is only used if the given property exists. With a repository where this property is missing, the index is not used. With blue-green deployments, it is possible that two versions of an application are running at the same time, with different/libsfolders. This settings therefore allows to enable or disable index usage depending on the version in use. (This index is still updated even if the node / property does not exist, so this setting only affects index usage for queries.) This option is supported for indexes of typeluceneandproperty.@since Oak 1.10.0 - blobSize
- Default value 32768 (32kb).
- Size in bytes used for splitting the index files when storing them
- functionName
- Name to be used to enable index usage with native query support.
- name
- Deprecated. Optional property.
- Captures the name of the index which is used while logging
- indexPath
- Deprecated. Optional string property to specify index path.
- Path of the index definition in the repository. For e.g. if the index
definition is specified at
/oak:index/lucenethen set this path inindexPath
Indexing Rules
Indexing rules define which types of nodes and properties are indexed. An
index configuration can define one or more indexingRules for different
nodeTypes.
fulltextIndex
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ app:Page
+ properties
- jcr:primaryType = "nt:unstructured"
+ publishedDate
- propertyIndex = true
- name = "jcr:content/publishedDate"
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ imageType
- propertyIndex = true
- name = "jcr:content/metadata/imageType"
Rules are defined per nodeType and each rule has one or more property definitions that determine which properties are indexed. Below is the canonical index definition structure
ruleName (nt:unstructured)
- inherited (boolean) = true
- indexNodeName (boolean) = false
- includePropertyTypes (string) multiple
+ properties (nt:unstructured)
Following are the config options which can be defined at the index rule level
- inherited
- Optional boolean property defaults to true
- Determines if the rule is applicable on exact match or can be applied if match is done on basis of nodeType inheritance
- includePropertyTypes
- Applicable when index is enabled for fulltext indexing
- For full text index defaults to include all types
- String array of property types which should be indexed. The values can be one specified in PropertyType Names
- indexNodeName
@since Oak 1.0.20, 1.2.5- Default to false. If set to true then index would also be created for node name.
This would enable faster evaluation of queries involving constraints on Node
name. For example
select [jcr:path] from [nt:base] where NAME() = 'kite'select [jcr:path] from [nt:base] where NAME() LIKE 'kite%'/jcr:root//kite/jcr:root//*[jcr:like(fn:name(), 'kite%')]/jcr:root//element(*, app:Asset)[fn:name() = 'kite']/jcr:root//element(kite, app:Asset)
Cost Overrides
By default, the cost of using this index is calculated follows: For each query,
the overhead is one operation. For each entry in the index, the cost is one.
The following only applies to compatVersion 2 only:
To use a lower or higher cost, you can set the following optional properties
in the index definition:
- costPerExecution (Double) = 1.0
- costPerEntry (Double) = 1.0
Please note that typically, those settings don't need to be explicitly set. Cost per execution is the overhead of one query. Cost per entry is the cost per node in the index. Using 0.5 means the cost is half, which means the index would be used more often (that is, even if there is a different index with similar cost).
Indexing Rule inheritance
indexRules are defined per nodeType and support nodeType inheritance. For
example while indexing any node the indexer would look up for applicable
indexRule for that node based on its primaryType. If a direct match is
found then that rule would be used otherwise it would look for rule for any
of the parent types. The rules are looked up in the order of there entry
under indexRules node (indexRule node itself is of type nt:unstructured
which has orderable child nodes)
If inherited is set to false on any rule then that rule would only be
applicable if exact match is found
Property Definitions
Each index rule consist of one or more property definition defined under
properties. Order of property definition node is important as some properties
are based on regular expressions. Below is the canonical property definition
structure
propNode (nt:unstructured)
- name (string)
- boost (double) = '1.0'
- index (boolean) = true
- useInExcerpt (boolean) = false
- analyzed (boolean) = false
- nodeScopeIndex (boolean) = false
- ordered (boolean) = false
- isRegexp (boolean) = false
- type (string) = 'undefined'
- propertyIndex (boolean) = false
- notNullCheckEnabled (boolean) = false
- nullCheckEnabled (boolean) = false
- excludeFromAggregation (boolean) = false
- weight (long) = 5
- function (string)
Following are the details about the above mentioned config options which can be defined at the property definition level
- name
- Property name. If not defined, then the property name is set to the node name.
See Property Names.
- isRegexp
- If set to true, then the property name is interpreted as a regular
expression, and the given definition is applicable for matching property names.
The expression must not match ‘/’.
^[^\/]*$- Matches all properties of this node.jcr:content/metadata/.*- This property definition is applicable for all properties of the child nodejcr:content/metadata
The regular expression only matches property names, and not intermediate nodes.
jcr:content/.*/.*does not index all properties for all children ofjcr:content. OAK-5187 is an open improvement to track supporting regular expression matching for intermediate child nodes. - boost
- If the property is included in
nodeScopeIndexthen it defines the boost done for the index value against the given property name. See Boost and Search Relevancy for more details - index
- Determines if this property should be indexed. Mostly useful for fulltext index where some properties need to be excluded from getting indexed.
- useInExcerpt
- Controls whether the value of a property should be used to create an excerpt. The value of the property is still full-text indexed when set to false, but it will never show up in an excerpt for its parent node. If set to true then property value would be stored separately within index causing the index size to increase. So set it to true only if you make use of excerpt feature
- nodeScopeIndex
- Control whether the value of a property should be part of fulltext index. That
is, you can do a
jcr:contains(., 'foo')and it will return nodes that have a string property that contains the word foo. Example/jcr:root/content//element(*, app:Asset)[jcr:contains(., 'image')]
In case of aggregation all properties would be indexed at node level by default if the property type is part of
includePropertyTypes. However, if there is an explicit property definition provided then it would only be included ifnodeScopeIndexis set to true.Note : If an index definition consists of any property with nodeScopeIndex set to true, then it will index the node name for all the nodes (with node type matching to or a child type of the one defined in the indexRule). This could result in large index size in case of indexRules on broader node types such as nt:base.
So it's advisable to use nodeScopeIndex for broader node types only if it's absolutely needed to support queries like
jcr:contains(., 'foo') - analyzed
- Set this to true if the property is used as part of
contains. Example/jcr:root/content//element(*, app:Asset)[jcr:contains(@type, 'image')]/jcr:root/content//element(*, app:Asset)[jcr:contains(jcr:content/metadata/@format, 'image')]
Binary properties can not be queried in this way; they can only be queried using the fulltext condition on the node, e.g.
jcr:contains(., 'image'). - ordered
- If the property is to be used in
order byclause to perform sorting then this should be set to true. This should be set to true only if the property is to be used to perform sorting as it increases the index size. Example/jcr:root/content//element(*, app:Asset)[jcr:contains(@type, 'image')] order by @size*/jcr:root/content//element(*, app:Asset)[jcr:contains(@type, 'image')] order by jcr:content/@jcr:lastModified
Refer to Lucene based Sorting for more details. Note that this is only supported for single value property. Enabling this on multi value property would cause indexing to fail.
Ordering is supported on properties, and on functions. To order on the name of the node, use the following query and index definition:
SELECT * FROM [sling:Folder] WHERE ISCHILDNODE('/content') ORDER BY NAME()- sling:Folder
- properties (nt:unstructured)
- nodeName (nt:unstructured)
- function (string) = ‘name()’
- propertyIndex (boolean) = true
- ordered (boolean) = true
- nodeName (nt:unstructured)
- properties (nt:unstructured)
- type
- JCR Property type. Can be one of
Date,Boolean,Double,String,Long, orBinary. Mostly inferred from the indexed value. However in some cases where same property type is not used consistently across various nodes then it would recommended to specify the type explicitly. For binary properties, you do not need to index the property separately. Binary properties are automatically added to the fulltext index (but only there), if the following conditions are met:- The node is part of the index (the node type or mixin matches),
- The
jcr:mimeTypeof this node is set - The mime type is indexed (see the Tika configuration).
- propertyIndex
- Whether the index for this property is used for equality conditions, ordering,
and
is not nullconditions. Example query:/jcr:root/content//element(*, app:Asset)[@status = 'test']
Binary properties can not be queried in this way; they can only be queried using the fulltext condition on the node, e.g.
jcr:contains(., 'image'). - notNullCheckEnabled
- Since 1.1.8
- If the property is checked for
is not nullthen this should be set to true. To reduce the index size, this should only be enabled for nodeTypes that are not generic.- /jcr:root/content//element(*, app:Asset)[jcr:content/@excludeFromSearch]
For details, see IS NOT NULL support.
- nullCheckEnabled
- Since 1.0.12
- If the property is checked for
is nullthen this should be set to true. This should only be enabled for nodeTypes that are not generic as it leads to index entry for all nodes of that type where this property is not set./jcr:root/content//element(*, app:Asset)[not(jcr:content/@excludeFromSearch)]
It would be better to use a query which checks for property existence or property being set to specific values as such queries can make use of index without any extra storage cost.
For details, see IS NULL support.
- excludeFromAggregation
- Since 1.0.27, 1.2.11
- If set to true, the property is excluded from aggregation OAK-3981
- function
- Since 1.5.11, 1.6.0, 1.42.0
- Function, for function-based indexing.
- dynamicBoost
- Since 1.28.0
- Enable dynamic boost
- weight
- Allows to override the estimated number of entries per value, which affects the cost of the index.
- Since 1.6.3: if
weightis set to0, then this property is assumed not to reduce the cost. Queries that contain only this condition should not use that index. See OAK-5899 for details. - Since 1.7.11: if
weightis set to10, then the estimated number of unique entries is 10. This means, the cost is reduced by a factor of about 10, for queries that contain this condition. See OAK-6735 for details. - Since 1.10: the default value is now
5. See OAK-7379 for details. - sync
- Since 1.8.0, OAK-6535
- Changes to the content are available in the index as soon as they are committed. Requires “propertyIndex=true”. Relative properties and notNullCheckEnabled are not supported.
- See Hybrid Indexes for details.
- unique
- Since 1.8.0, OAK-6535
- Requires “sync=true”. Enforces unique property values in the content.
- See Hybrid Indexes for details.
Property Names
Property name can be one of the following:
- Simple name - like
assetTypeetc. These are used for properties which are defined directly on the indexed node. - Relative name - like
jcr:content/metadata/title. These are used for properties which are defined relative to the node being indexed. For relative properties, one wildcard (*) is supported instead of a node name:*/coloraggregates the values of the propertycolorof all direct child nodes. - Regular Expression -
if
isRegexpis true, then the property name is a regular expression, for example.*. In this case, the properties whose name match the given pattern are indexed. The value can refer to relative properties likejcr:content/metadata/dc:.*$, which indexes all property names starting withdcfrom node with relative pathjcr:content/metadata. - The string
:nodeName- this special case indexes node name as if it's a virtual property of the node being indexed. Setting this along withnodeScopeIndex = trueis akin to settingindexNodeName = trueon indexing rule (@since Oak 1.3.15, 1.2.14). Ordering is not supported. For ordering, usefunction = "name()"instead.
Limitations:
- Special properties such as
jcr:path,jcr:scorecan not be indexed. To index the path, use function based indexing:function = "path()". - Properties where the
namevalue starts with a dot (eg../jcr:content/metadata/title) are silently ignored, for backward compatibility. That means the property is not indexed, and when querying, the index will ignore conditions on this field.
Evaluate Path Restrictions
Lucene index provides support for evaluating path restrictions natively. Consider a query like
select * from [app:Asset] as a where isdescendantnode(a, [/content/app/old]) AND contains(*, 'white')
By default, the index would return all node which contain white and Query
engine would filter out nodes which are not under /content/app/old. This
can perform slow if lots of nodes are not under that path. To speed up such
queries one can enable evaluatePathRestrictions in Lucene index and index
would only return nodes which are under /content/app/old.
Enabling this feature would incur cost in terms of slight increase in index size. Refer to OAK-2306 for more details.
Include and Exclude paths from indexing
@since Oak 1.0.14, 1.2.3
Sometimes, only nodes under certain paths should be indexed (includedPaths).
If includedPaths is used, then queryPaths should be set to the same value(s).
This is because excludedPaths and includedPaths don't
affect the index selection logic for a query.
Path restrictions of queries are only checked against queryPaths.
The follow index definition causes nodes under /content and /home to be indexed:
/oak:index/abc
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- includedPaths = ["/content", "/home"]
- queryPaths = ["/content", "/home"]
Sometimes, certain path should be excluded (excludedPaths),
e.g. transient system data.
If the application stores logs under /var/log, and this data is
not supposed to be indexed, then it can be excluded, by setting
excludedPaths to ["/var/log"].
However, it is typically better to set includedPaths and queryPaths.
queryPaths
If you need to ensure that a given index only gets used for query with specific
path restrictions then you need to specify those paths in queryPaths.
In most cases, if queryPaths is used, then includedPaths should be set to the same
value, to reduce the index size.
For example if includedPaths and queryPaths are set to ["/content", "/home"].
The index would be used for queries below /content as well as for queries below
/home. But it won't be used for queries without path restriction, or for queries below
/tmp.
Usage
Key points to consider while using includedPaths, queryPaths, and excludedPaths,
-
includedPathsandqueryPathsshould typically be set to the same value(s). Also, the query should use a matching path restriction. That way, the index size can be reduced, and there are no surprises that queries don't show data that is stored in the repository. -
Only data should be indexes that is needed. This shrinks the index size, and speeds up indexing.
-
Use
includedPaths,excludedPaths, andqueryPathswith caution. If the wrong paths are excluded, then some nodes might not show up in query results that should. -
Sub-root index definitions (e.g.
/test/oak:index/index-def-node) -excludedPathsandincludedPathsneed to be relative to the path that index is defined for. If the condition is supposed to be put for/test/awhere the index definition is at/test/oak:index/index-def-nodethen/aneeds to be put as value ofexcludedPathsorincludedPaths. On the other hand,queryPathsremains to be an absolute path. So, for the example above,queryPathswould get the value/test/a.
See to OAK-2599 for more details.
Aggregation
Sometimes it is useful to include the contents of descendant nodes into a single node to easier search on content that is scattered across multiple nodes.
Oak allows you to define index aggregates based on relative path patterns and primary node types. Changes to aggregated items cause the main item to be reindexed, even if it was not modified.
Please note that aggregation does not support nodeType inheritance. To support aggregation on child nodeTypes, they need to be explicitly defined as a separate aggregation configuration in the index definition.
Aggregation configuration is defined under the aggregates node under index
configuration. The following example creates an index aggregate on nt:file that
includes the content of the jcr:content node:
fulltextIndex
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ aggregates
+ nt:file
+ include0
- path = "jcr:content"
By default, all properties whose type matches includePropertyTypes and are
part of child nodes as per the aggregation pattern are included for indexing.
For excluding certain properties define a property definition with relative
path and set excludeFromAggregation to true. Such properties would then be
excluded from fulltext index
For a given nodeType multiple includes can be defined. Below is the aggregate definition structure for any specific include rule
aggregateNodeInclude (nt:unstructured)
- path (string) mandatory
- primaryType (string)
- relativeNode (boolean) = false
Following are the details about the above mentioned config options which can be defined as part of aggregation include. (Refer to OAK-2268 for implementation details)
- path
- Path pattern to include. Example
jcr:content- Name explicitly specified*- Any child node at depth 1*/*- Any child node at depth 2
- primaryType
- Restrict the included nodes to a certain type. The restriction would be
applied on the last node in given path
+ aggregates + nt:file + include0 - path = "jcr:content" - primaryType = "nt:resource" - relativeNode
- Boolean property indicates that query can be performed against specific node
For example for following content
+ space.txt (app:Asset) + renditions (nt:folder) + original (nt:file) + jcr:content (nt:resource) - jcr:dataAnd a query like
select * from [app:Asset] where contains([renditions/original/*], "pluto")Following index configuration would be required
fulltextIndex - jcr:primaryType = "oak:QueryIndexDefinition" - compatVersion = 2 - type = "lucene" - async = "async" + aggregates + nt:file + include0 - path = "jcr:content" + app:Asset + include0 - path = "renditions/original" - relativeNode = true + indexRules - jcr:primaryType = "nt:unstructured" + app:Asset
Aggregation and Recursion
While performing aggregation the aggregation rules are again applied on node
being aggregated. For example while aggregating for app:Asset above when
renditions/original/* is being aggregated then aggregation rule would again
be applied. In this case as renditions/original is nt:file then aggregation
rule applicable for nt:file would be applied. Such a logic might result in
recursion. (See JCR-2989 for details).
For such case reaggregateLimit is set on aggregate definition node and
defaults to 5
+ aggregates
+ app:Asset
- reaggregateLimit (long) = 5
+ include0
- path = "renditions/original"
- relativeNode = true
Analyzers
If no analyzer is specified, then OakAnalyzer is used, which uses the
Apache Lucene StandardTokenizer, the LowerCaseFilter,
and the WordDelimiterFilter with the following options:
GENERATE_WORD_PARTS, STEM_ENGLISH_POSSESSIVE, and GENERATE_NUMBER_PARTS.
@since Oak 1.5.5, 1.4.7, 1.2.19
Unless custom analyzer is explicitly configured (as documented below), the built-in analyzer
can be configured to include the original term as well (PRESERVE_ORIGINAL). This is
controlled by setting boolean property indexOriginalTerm on the analyzers node:
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
+ analyzers
- indexOriginalTerm = true
(See OAK-4516 for details)
@since Oak 1.2.0
Analyzers can be configured as part of index definition via analyzers node.
The default analyzer can be configured via analyzers/default node
+ sampleIndex
- jcr:primaryType = "oak:QueryIndexDefinition"
+ analyzers
+ default
...
Specify analyzer class directly
If any of the out of the box analyzer is to be used then it can configured directly
+ analyzers
+ default
- class = "org.apache.lucene.analysis.standard.StandardAnalyzer"
- luceneMatchVersion = "LUCENE_47" (optional)
To confirm to specific version specify it via luceneMatchVersion otherwise Oak
would use a default version depending on version of Lucene it is shipped with.
One can also provide a stopword file via stopwords nt:file node under
the analyzer node
+ analyzers
+ default
- class = "org.apache.lucene.analysis.standard.StandardAnalyzer"
- luceneMatchVersion = "LUCENE_47" (optional)
+ stopwords (nt:file)
Create analyzer via composition
Analyzers can also be composed based on Tokenizers, TokenFilters and
CharFilters. This is similar to the support provided in Solr where you can
configure analyzers in xml.
In this case, the analyzer class property needs to be removed.
The tokenizer needs to be specified,
all the other components (e.g. charFilters, Synonym) are optional.
+ analyzers
+ default
+ charFilters (nt:unstructured) // the filters needs to be ordered
+ HTMLStrip
+ Mapping
+ tokenizer
- name = "Standard"
+ filters (nt:unstructured) // the filters needs to be ordered
+ LowerCase
+ Stop
- words = "stop1.txt, stop2.txt"
+ stop1.txt (nt:file)
+ stop2.txt (nt:file)
+ PorterStem
+ Synonym
- synonyms = "synonym.txt"
+ synonym.txt (nt:file)
Examples
To convert umlauts using ASCII folding, use the following. (ASCII folding converts characters to Basic Latin where possible. This includes umlauts, characters with accents, and so on.)
+ analyzers
+ default
+ tokenizer
- name = "Standard"
+ filters (nt:unstructured) // the filters needs to be ordered
+ ASCIIFolding
For stemming support, use:
1. Use an analyzer which has stemming included by default e.g. EnglishAnalyzer which has PorterStemFilter.
+ analyzers
+ default
- class = "org.apache.lucene.analysis.en.EnglishAnalyzer"
2. Use stemming as part of analyzer composition (using org.apache.lucene.analysis.hunspell.HunspellStemFilterFactory)
+ analyzers
+ default
+ tokenizer
- name = "Standard"
+ filters (nt:unstructured) // the filters needs to be ordered
+ LowerCase
+ HunspellStem
- dictionary = "en_gb.dic"
- affix = "en_gb.aff"
+ en_gb.aff (nt:file)
+ en_gb.dic (nt:file)
Points to note
- Name of filters, charFilters and tokenizer are formed by removing the
factory suffixes. So
- org.apache.lucene.analysis.standard.StandardTokenizerFactory ->
Standard - org.apache.lucene.analysis.charfilter.MappingCharFilterFactory ->
Mapping - org.apache.lucene.analysis.core.StopFilterFactory ->
Stop
- org.apache.lucene.analysis.standard.StandardTokenizerFactory ->
- Any config parameter required for the factory is specified as property of
that node
- If the factory requires to load a file e.g. stop words from some file then
file content can be provided via creating child
nt:filenode of the filename - The property value MUST be of type
String. No other JCR type should be used for them like array or integer etc
- If the factory requires to load a file e.g. stop words from some file then
file content can be provided via creating child
- The analyzer-chain processes text from nodes as well text passed in query. So,
do take care that any mapping configuration (e.g. synonym mappings) factor in
the chain of analyzers.
E.g a common mistake for synonym mapping would be to have
domain => Rangewhile there's a lower case filter configured as well (see the example above). For such a setup an indexed valuedomainwould actually get indexed asRange(mapped value doesn't have lower case filter below it) but a query forRangewould actually query forrange(due to lower case filter) and won't give the result (as might be expected). An easy work-around for this example could be to have lower case mappings i.e. just usedomain => range. - Precedence: Specifying analyzer class directly has precedence over analyzer configuration
by composition. If you want to configure analyzers by composition then analyzer class
MUST NOT be specified. In-build analyzer has least precedence and comes into play only
if no custom analyzer has been configured. Similarly, setting
indexOriginalTermon analyzers node to modify behavior of in-built analyzer also works only when no custom analyzer has been configured. - To determine list of supported factories have a look at Lucene javadocs for
- Oak support for composing analyzer is based on Lucene. So some helpful docs around this
- When defining synonyms:
- in the synonym file, lines like plane, airplane, aircraft refer to tokens that are mutual synoyms whereas lines
like
plane => airplanerefer to one way synonyms, so that plane will be expanded to airplane but not vice versa - continuing with the point above, since oak would use the same analyzer for indexing as well as querying, using one-way synonyms in any practical way is not supported at the moment.
- special characters have to be escaped
- multi word synonyms need particular attention (see https://lucidworks.com/post/solution-for-multi-term-synonyms-in-lucenesolr-using-the-auto-phrasing-tokenfilter/)
- in the synonym file, lines like plane, airplane, aircraft refer to tokens that are mutual synoyms whereas lines
like
Note that currently only one analyzer can be configured per index. Its not possible to specify separate analyzer for query and index time currently.
Codec
Name of Lucene Codec to use. By default, if the index involves
fulltext indexing then Oak Lucene uses OakCodec which disables compression.
Due to this the index size may grow large. To enable compression you can set
the codec to Lucene46
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- codec = "Lucene46"
Refer to OAK-2853 for details. Enabling the Lucene46 codec
would lead to smaller and compact indexes.
Boost and Search Relevancy
@since Oak 1.2.5
When fulltext indexing is enabled then internally Oak would create a fulltext
field which consists of text extracted from various other fields i.e. fields
for which nodeScopeIndex is true. This allows search like
/jcr:root/content//*[jcr:contains(., 'foo')] to perform search across any indexable field
containing foo (See contains function for details)
In certain cases its desirable that those nodes where the searched term is present in a specific property are ranked higher (come earlier in search result) compared to those node where the searched term is found in some other property.
In such cases it should be possible to boost specific text contributed by individual property. Meaning that if a title field is boosted more than description, then search result would those node coming earlier where searched term is found in title field
For that to work ensure that for each such property (which need to be preferred)
both nodeScopeIndex and analyzed are set to true. In addition, you can specify
boost property so give higher weightage to values found in specific property
Note that even without setting explicit boost and just setting nodeScopeIndex
and analyzed to true would improve the search result due to the way
Lucene does scoring. Internally Oak would create separate Lucene
fields for those jcr properties and would perform a search across all such fields.
For more details refer to OAK-3367
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ description
- nodeScopeIndex = true
- analyzed = true
- name = "jcr:content/metadata/jcr:description"
+ title
- analyzed = true
- nodeScopeIndex = true
- name = "jcr:content/metadata/jcr:title"
- boost = 2.0
With above index config a search like
SELECT * FROM [app:Asset]
WHERE CONTAINS(., 'Batman')
Would have those node (of type app:Asset) come first where Batman is found in
jcr:title. While those nodes where search text is found in other field
like aggregated content would come later
Effective Index Definition
@since Oak 1.6
Prior to Oak 1.6 index definition as defined in content was directly used for query execution and indexing. It was possible that index definition is modified in incompatible way and that would start affecting the query execution leading to inconsistent result.
Since Oak 1.6 the index definitions are cloned upon reindexing and stored in a hidden structure. For further incremental indexing and for query plan calculation the stored index definition is used. So any changes done post reindex to index definition would not be applicable until a reindex is done.
There would be some cases where changes in index definition does not require a reindex. For e.g. if a new property is being introduced in content model and no prior content exist with such a property then it's safe to index such a property without doing a reindex. For such cases user must follow below steps
- Make the required changes
- Set
refreshproperty totruein index definition node - Save the changes
On next async indexing cycle this flag would be picked up and stored index definition would be refreshed. Post this the flag would be automatically removed and a log message would be logged. You would also see a log message like below
LuceneIndexEditorContext - Refreshed the index definition for [/oak:index/fooLuceneIndex]
To simplify troubleshooting the stored index definition can be accessed from LuceneIndexMBean via
getStoredIndexDefinition operation. It would dump the string representation of stored NodeState
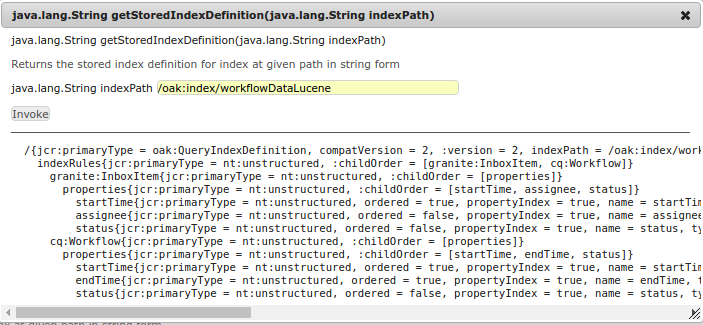
This feature can be disabled by setting OSGi property disableStoredIndexDefinition for LuceneIndexProviderService
to true. Once disable any change in index definition would start effecting the query plans
Refer to OAK-4400 for more details.
Generating Index Definition
To simplify generating index definition suitable for evaluating certain set of queries you can make use of the Oak Tools. Here you can provide a set of queries and then it would generate the suitable index definitions for those queries.
Note that you would still need to tweak the definition for aggregation, path include exclude etc as that data cannot be inferred from the query
Near Real Time Indexing
@since Oak 1.6
Refer to Near realtime indexing for more details
LuceneIndexProvider Configuration
Some of the runtime aspects of the Oak Lucene support can be configured via OSGi
configuration. The configuration needs to be done for PID org.apache .jackrabbit.oak.plugins.index.lucene.LuceneIndexProviderService
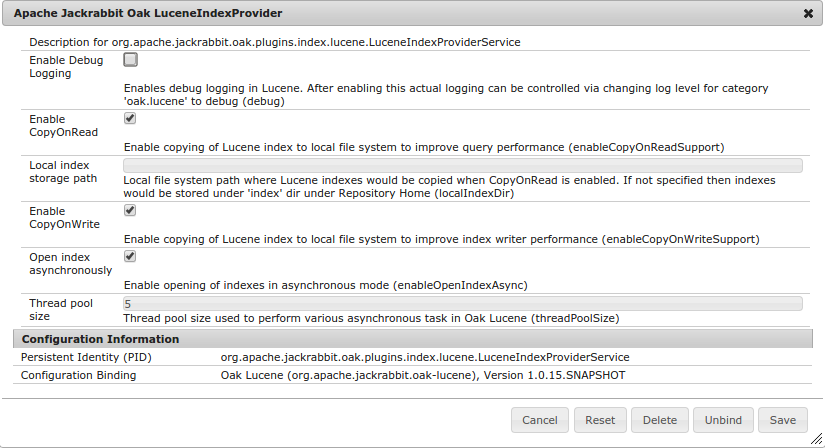
- enableCopyOnReadSupport
- Enable copying of Lucene index to local file system to improve query performance. See Copy Indexes On Read
- enableCopyOnWriteSupport
- Enable copying of Lucene index to local file system to improve indexing performance. See Copy Indexes On Write
- localIndexDir
- Directory to be used for when copy index files to local file system. To be
specified when
enableCopyOnReadSupportis enabled - prefetchIndexFiles
- Prefetch the index files when CopyOnRead is enabled. When enabled all new Lucene index files would be copied locally before the index is made available to QueryEngine (1.0.17,1.2.3)
- debug
- Boolean value. Defaults to
false - If enabled then Lucene logging would be integrated with Slf4j
Tika Config
@since Oak 1.0.12, 1.2.3
Oak Lucene uses Apache Tika to extract the text from binary content
+ tika
- maxExtractLength (long) = -10
+ config.xml (nt:file)
+ jcr:content
- jcr:data = //config xml binary content
Oak uses a default config. To use a custom config specify
the config file via tika/config.xml node in index config.
- maxExtractLength
- Limits the number of characters that are extracted by the Tika parse. A negative
value indicates a multiple of
maxFieldLengthand a positive value is used as is- maxExtractLength = -10, maxFieldLength = 10000 -> Actual value = 100000
- maxExtractLength = 1000 -> Actual value = 1000
Mime type usage
A binary is only indexed if there is an associated property jcr:mimeType defined
and that is supported by Tika. By default, indexer uses TypeDetector
instead of default DefaultDetector which relies on the jcr:mimeType to pick up the
right parser.
Mime type mapping
@since Oak 1.7.7
In certain circumstances, it may be desired to pass a value other than the jcr:mimeType property
into the Tika parser. For example, this would be necessary if a binary has an application-specific
mime type, but is parsable by the standard Tika parser for some generic type. To support these cases,
create a node structure under the tika/mimeTypes node following the mime type structure, e.g.
+ tika
+ mimeTypes (nt:unstructured)
+ application (nt:unstructured)
+ vnd.mycompany-document (nt:unstructured)
- mappedType = application/pdf
When this index is indexing a binary of type application/vnd.mycompany-document it will force Tika
to treat it as a binary of type application/pdf.
Non Root Index Definitions
Lucene index definition can be defined at any location in repository and need not always be defined at root. For example if your query involves path restrictions like
select * from [app:Asset] as a where ISDESCENDANTNODE(a, '/content/companya') and [format] = 'image'
Then you can create the required index definition say assetIndex at
/content/companya/oak:index/assetIndex. In such a case that index would
contain data for the subtree under /content/companya
Function-Based Indexing
@since Oak 1.5.11, 1.6.0, 1.42.0
Function-based indexes can for example allow to search (or order by) the lower case version of a property. For more details see OAK-3574 and OAK-9625.
For example using the index definition
uppercaseLastName
- function = "fn:upper-case(@lastName)"
- propertyIndex = true
- ordered = true
This allows to search for, and order by, the lower case version of the property “lastName”. Example functions:
- fn:upper-case(@data)
- fn:lower-case(test/@data)
- fn:lower-case(fn:name())
- fn:lower-case(fn:local-name())
- fn:string-length(test/@data)
- first([alias])
- upper([data])
- lower([test/data])
- lower(name())
- lower(localname())
- length([test/data])
- length(name())
- name()
- path()
Indexing multi-valued properties is supported. Relative properties are supported (except for “..” and “.”). Range conditions are supported (‘>’, ‘>=’, ‘<=’, ‘<’).
The functions path(), first(), and name() require Oak version 1.42.0 or newer.
Dynamic Boost
@since Oak 1.28.0
To enable the feature, add a property to be indexed, e.g.:
dynamicBoost
- dynamicBoost = true (Boolean)
- propertyIndex = true
- name = jcr:content/metadata/predictedTags/.* (String)
- isRegexp = true (Boolean)
That way, if a node jcr:content/metadata/predictedTags is added (for the indexed node type),
then dynamic boost is used. It will read the child nodes of that node
(jcr:content/metadata/predictedTags) and for each node it will read:
- name (String)
- confidence (Double)
It will then add a field, for each token of the “name” property,
with boost set to the confidence.
This is a replacement for the IndexFieldProvider.
See also OAK-8971.
Tag values that exceed the configured maxTagLength (default 100) are skipped during indexing.
This prevents unexpectedly long values from being indexed as dynamic boost tags.
The limit can be changed by setting the maxTagLength property on the index definition,
or disabled entirely by setting it to -1. See OAK-12101.
Additionally, the maximum number of dynamic boost tags indexed per document can be controlled
with the maxDynamicBoostCount property (default 50). When the number of collected tags exceeds this limit,
tags are sorted by confidence in descending order and only the top N are indexed.
Set to -1 to disable the limit entirely. See OAK-12117.
Native Query and Index Selection
@deprecated Oak 1.46
Oak query engine supports native queries like
/jcr:root/content//*[rep:native('lucene', 'name:(Hello OR World)')]
If multiple Lucene based indexes are enabled on the system and you need to
make use of specific Lucene index like /oak:index/assetIndex then you can
specify the index name via functionName attribute on index definition.
For example for assetIndex definition like
luceneAssetIndex
- jcr:primaryType = "oak:QueryIndexDefinition"
- type = "lucene"
...
- functionName = "lucene-assetIndex"
Executing following query would ensure that Lucene index from assetIndex
should be used
/jcr:root/content//*[rep:native('lucene-assetIndex', 'name:(Hello OR World)')]
Persisting indexes to FileSystem
By default, Lucene indexes are stored in the NodeStore. If required they can
be stored on the file system directly
- jcr:primaryType = "oak:QueryIndexDefinition"
- type = "lucene"
...
- persistence = "file"
- path = "/path/to/store/index"
To store the Lucene index in the file system, in the Lucene index definition
node, set the property persistence to file, and set the property path
to the directory where the index should be stored. Then start reindexing by
setting reindex to true.
Note that this setup would only for those non cluster NodeStore. If the
backend NodeStore supports clustering then index data would not be
accessible on other cluster nodes
CopyOnRead
Lucene indexes are stored in NodeStore. Oak Lucene provides a custom directory
implementation which enables Lucene to load index from NodeStore. This
might cause performance degradation if the NodeStore storage is remote. For
such case Oak Lucene provide a CopyOnReadDirectory which copies the index
content to a local directory and enables Lucene to make use of local
directory based indexes while performing queries.
At runtime various details related to copy on read features are exposed via
CopyOnReadStats MBean. Indexes at JCR path e.g. /oak:index/assetIndex
would be copied to <index dir>/<hash of jcr path>. To determine mapping
between local index directory and JCR path refer to the MBean details
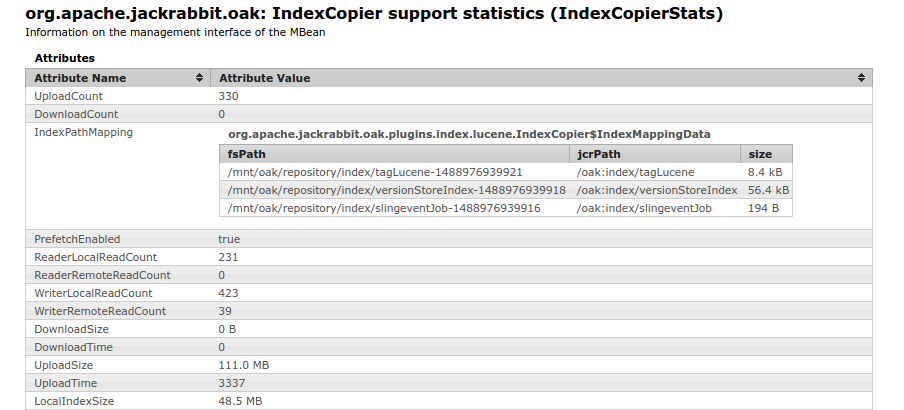
For more details refer to OAK-1724. This feature can be enabled via Lucene Index provider service configuration
With Oak 1.0.13 this feature is now enabled by default.
CopyOnWrite
@since Oak 1.0.15, 1.2.3
Similar to CopyOnRead feature Oak Lucene also supports CopyOnWrite to enable faster indexing by first buffering the writes to local filesystem and transferring them to remote storage asynchronously as the indexing proceeds. This should provide better performance and hence faster indexing times.
indexPath
Not required from Oak 1.6 , 1.4.7+
To speed up the indexing with CopyOnWrite you would also need to set indexPath
in index definition to the path of index in the repository. For e.g. if your
index is defined at /oak:index/lucene then value of indexPath should be set
to /oak:index/lucene. This would enable the indexer to perform any read
during the indexing process locally and thus avoid costly read from remote.
For more details refer to OAK-2247. This feature can be enabled via Lucene Index provider service configuration
Lucene Index MBeans
Oak Lucene registers a JMX bean LuceneIndex which provide details about the
index content e.g. size of index, number of documents present in index etc
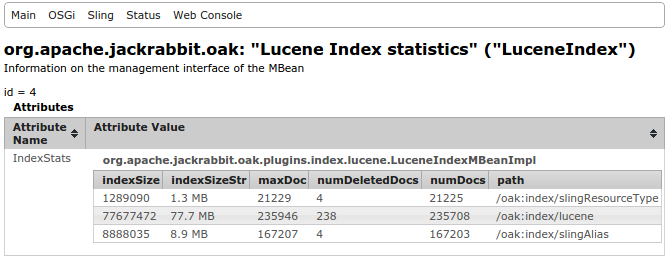
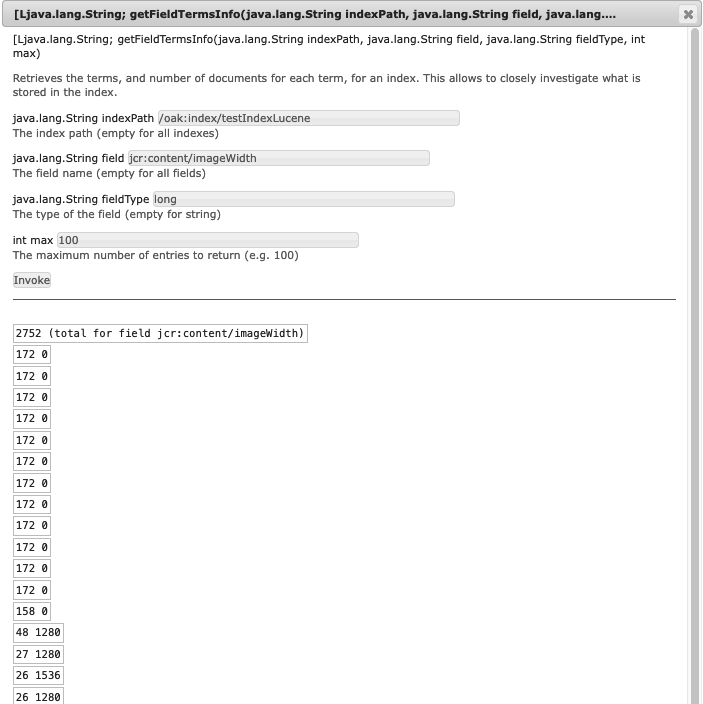
This MBean supports retrieving index fields and terms using the getFieldTermsInfo(java.lang.String indexPath, java.lang.String field, int max)
and the getFieldTermsInfo(java.lang.String indexPath, java.lang.String field, java.lang.String fieldType, int max) methods.
The first method always assumes the return type is a String, the second method allows you to specify the return type as either:
- String (value: String, java.lang.String)
- Long (value: long, java.lang.Long)
- Integer (value: int, java.lang.Integer)
For example:
Active Index Files Collection
@since Oak 1.7.12
Lucene indexing for moderately active repository creates a lot of deleted files. This creates excessive load for usual mark-sweep garbage collection. Since, blobs related to indexed data are explicitly made unique, it's safe to delete them as soon as index node referring that blob is deleted.
Such active deletion of index blobs was implemented in OAK-2808. The
feature periodically deletes blobs which are deleted from the index. This ‘period’
can be controlled by deletedBlobsCollectionInterval property in
Lucene Index provider service configuration.
The feature would only delete blobs which have been deleted before a certain time.
The task to actually purge blobs from datastore is performed by jmx operation. Jmx bean
for the operation is org.apache.jackrabbit.oak:name=Active lucene files collection,type=ActiveDeletedBlobCollector
and the operation is startActiveCollection().
To disable active deletion in a certain installation, set the system property oak.active.deletion.disabled.
Analyzing created Lucene Index
Luke is a handy development and diagnostic tool, which accesses already existing Lucene indexes and allows you to display index details. In Oak, Lucene index files are not directly accessible. To enable analyzing the index files via Luke follow below mentioned steps
-
Download the Luke version which includes the matching Lucene jars used by Oak. As of Oak 1.0.8 release the Lucene version used is 4.7.1. So download the jar from here
$wget https://github.com/DmitryKey/luke/releases/download/4.7.0/luke-with-deps.jar -
Use the Oak Console to dump the Lucene index files to a directory. Use the
lc dumpcommand as follows:$ java -jar oak-run-*.jar console /path/to/oak/repository Apache Jackrabbit Oak 1.1-SNAPSHOT Jackrabbit Oak Shell (Apache Jackrabbit Oak 1.1-SNAPSHOT, JVM: 1.7.0_55) Type ':help' or ':h' for help. ------------------------------------------------------------------------- /> lc info /oak:index/lucene Index size : 74.1 MB Number of documents : 235708 Number of deleted documents : 231 /> lc dump info /> lc dump /path/to/dump/index/lucene /oak:index/lucene Copying Lucene indexes to [/path/to/dump/index/lucene] Copied 74.1 MB in 1.209 s /> lc dump /path/to/dump/index/slingAlias /oak:index/slingAlias Copying Lucene indexes to [/path/to/dump/index/lucene-index/slingAlias] Copied 8.5 MB in 218.7 ms /> -
Afterwards, open the index via Luke. Oak Lucene uses a custom Codec. So oak-lucene jar needs to be included in Luke classpath for it to display the index details
$ java -XX:MaxPermSize=512m -cp luke-with-deps.jar:oak-lucene-1.0.8.jar org.getopt.luke.Luke
From the Luke UI shown you can access various details.
Pre-Extracting Text from Binaries
Refer to pre-extraction via oak-run.
Advanced search features
Suggestions
@since Oak 1.1.17, 1.0.15
In order to use Lucene index to perform search suggestions, the index definition
node (the one of type oak:QueryIndexDefinition) needs to have the compatVersion
set to 2, then one or more property nodes, depending on use case, need to have
the property useInSuggest set to true, such setting controls from which
properties terms to be used for suggestions will be taken.
Once the above configuration has been done, by default, the Lucene suggester is
updated every 10 minutes but that can be changed by setting the property
suggestUpdateFrequencyMinutes in suggestion node under the index definition
node to a different value.
Note that up till Oak 1.3.14/1.2.14, suggestUpdateFrequencyMinutes was to be setup at
index definition node itself. That is is still supported for backward compatibility,
but having a separate suggestion node is preferred.
Sample configuration for suggestions based on terms contained in jcr:description
property.
/oak:index/lucene-suggest
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ suggestion
- suggestUpdateFrequencyMinutes = 20
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ jcr:description
- propertyIndex = true
- analyzed = true
- useInSuggest = true
@since Oak 1.3.12, 1.2.14 the index Analyzer can be used to perform a have more fine grained suggestions, e.g. single words
(whereas default suggest configuration returns entire property values, see [OAK-3407]: https://issues.apache.org/jira/browse/OAK-3407).
Analyzed suggestions can be enabled by setting “suggestAnalyzed” property to true, e.g.:
/oak:index/lucene-suggest
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ suggestion
- suggestUpdateFrequencyMinutes = 20
- suggestAnalyzed = true
Note that up till Oak 1.3.14/1.2.14, suggestAnalyzed was to be setup at index definition node itself. That is still
supported for backward compatibility, but having a separate suggestion node is preferred.
Setting up useInSuggest=true for a property definition having name=:nodeName would add node names to
suggestion dictionary (See property name for node name indexing)
Since, Oak 1.3.16/1.2.14, very little support exists for queries with ISDESCENDANTNODE constraint to subset suggestions
on a sub-tree. It requires evaluatePathRestrictions=true on index definition. e.g.
select [rep:suggest()] from [nt:base] where suggest('in ') and issamenode('/')
or
/jcr:root/content//*[rep:suggest('in ')]/(rep:suggest())
Note, the subset is done by filtering top 10 suggestions. So, it's possible to get no suggestions for a subtree query, if top 10 suggestions are not part of that subtree. For details look at OAK-3994 and related issues.
Spellchecking
@since Oak 1.1.17, 1.0.13
In order to use Lucene index to perform spellchecking, the index definition node
(the one of type oak:QueryIndexDefinition) needs to have the compatVersion
set to 2, then one or more property nodes, depending on use case, need to have
the property useInSpellcheck set to true, such setting controls from which
properties terms to be used for spellcheck corrections will be taken.
Sample configuration for spellchecking based on terms contained in jcr:title
property.
Since Oak 1.3.11/1.2.14, each suggestion would be returned per row.
/oak:index/lucene-spellcheck
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ jcr:title
- propertyIndex = true
- analyzed = true
- useInSpellcheck = true
Since, Oak 1.3.16/1.2.14, very little support exists for queries with ISDESCENDANTNODE constraint to subset suggestions
on a sub-tree. It requires evaluatePathRestrictions=true on index definition. e.g.
select [rep:spellcheck()] from [nt:base] as a where spellcheck('helo') and issamenode(a, '/')
or
/jcr:root/a/b//*[rep:spellcheck('in 201')]/(rep:spellcheck())
Note, the subset is done by filtering top 10 spellchecks. So, it's possible to get no results for a subtree query, if top 10 spellchecks are not part of that subtree. For details look at OAK-3994 and related issues.
Facets
@since Oak 1.3.14
Lucene property indexes can also be used for retrieving facets, in order to do so the property facets must be set to
true on the property definition.
/oak:index/lucene-with-facets
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ tags
- facets = true
- propertyIndex = true
Specific facet related features for Lucene property index can be configured in a separate facets node below the
index definition.
@since Oak 1.5.15 The no. of facets to be retrieved is configurable via the topChildren property, which defaults to 10.
/oak:index/lucene-with-more-facets
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ facets
- topChildren = 100
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ tags
- facets = true
- propertyIndex = true
By default, ACL checks are always performed on facets by the Lucene property index.
This is secure (no information leakage is possible), but can be slow.
The secure configuration property allows to configure how facet counts are performed.
@since Oak 1.6.16, 1.8.10, 1.9.13 secure property is a string with allowed values of secure, statistical and
insecure - secure being the default value. Before that secure was a boolean property and to maintain compatibility
false maps to insecure while true (default at the time) maps to secure.
The following configuration options are supported:
-
secure(the default) means all results of a query are checked for access permissions. Facets and counts returned by index reflect what is accessible to the given user. The query result therefore only reflects information the user has access rights for. This can be slow, specially for large result set. -
insecuremeans the facet counts are reported as stored in the index, without performing access rights checks. This setting may allow users to infer the existence of content to which they do not have access. It is recommended to use this setting only if either the index is guaranteed to only contain data that is public (e.g. a public subtree of the repository), or if the information is not sensitive. -
statisticalmeans the data is sampled randomly (default1000configurable viasampleSize), and ACL checks are performed on this sample. Facet counts returned are proportional to the percentage of accessible samples that were checked for ACL. Warning: this setting potentially leaks repository information the user that runs the query may not see. It must only be used if either the index is guaranteed to only contain data that is public (e.g. a public subtree of the repository), or if the leaked information is not sensitive. Do note that the beauty of sampling is that a sample size of1000has an error rate of 3% with 95% confidence, if ACLs are evenly distributed over the sampled data. However, often ACLs are not evenly distributed. Also, a low rate of accessible documents decreases chances to reach that average rate. To have a sense of expectation of error rate, here's how errors looked like in different scenarios of test runs with sample size of 1000 with error averaged over 1000 random runs for each scenario.
|-----------------|-----------------------|------------------------|
| Result set size | %age accessible nodes | Avg error in 1000 runs |
|-----------------|-----------------------|------------------------|
| 2000 | 5 | 5.79 |
| 5000 | 5 | 9.99 |
| 10000 | 5 | 10.938 |
| 100000 | 5 | 11.13 |
| | | |
| 2000 | 25 | 2.4192004 |
| 5000 | 25 | 3.8087976 |
| 10000 | 25 | 4.096 |
| 100000 | 25 | 4.3699985 |
| | | |
| 2000 | 50 | 1.3990011 |
| 5000 | 50 | 2.2695997 |
| 10000 | 50 | 2.5303981 |
| 100000 | 50 | 2.594599 |
| | | |
| 2000 | 75 | 0.80360085 |
| 5000 | 75 | 1.1929348 |
| 10000 | 75 | 1.4357346 |
| 100000 | 75 | 1.4272015 |
| | | |
| 2000 | 95 | 0.30958 |
| 5000 | 95 | 0.52715933 |
| 10000 | 95 | 0.5109484 |
| 100000 | 95 | 0.5481065 |
|-----------------|-----------------------|------------------------|
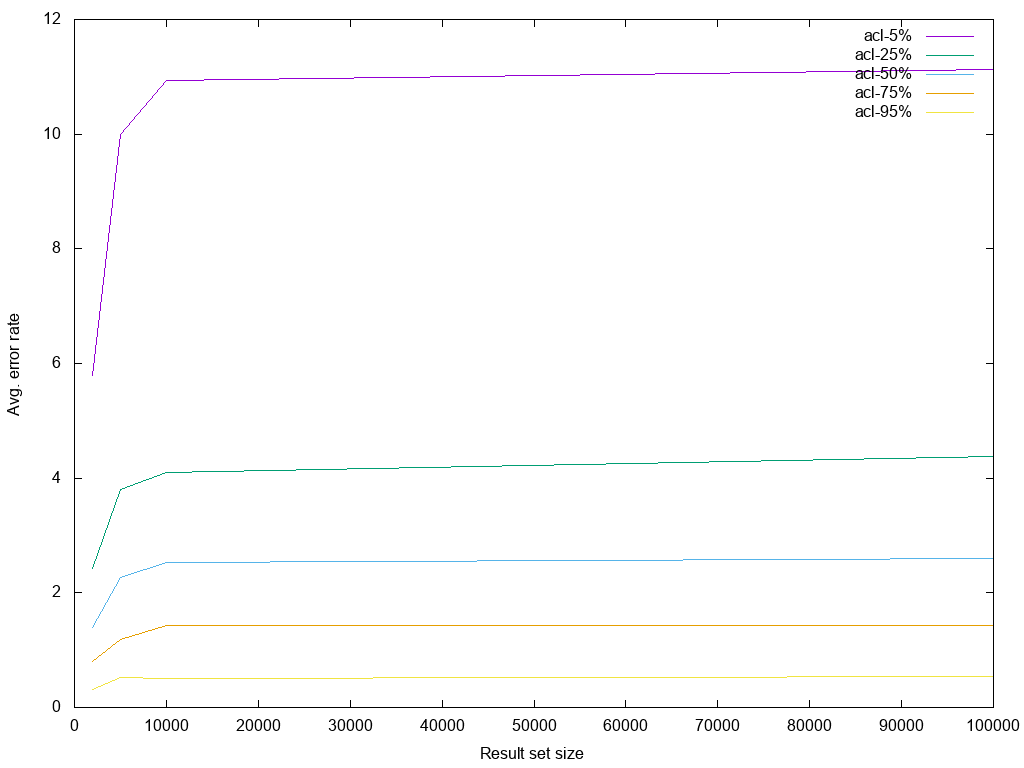
Notice that error rate does increase with large result set sizes but it flattens after around 10000 results. Also, note that even with 50% results being accessible, error rate averages at less that 3%.
So, in most cases, sampling size of 1000 should give fairly decent estimation of facet counts. On the off chance that
the setup is such that error rates are intolerable, sample size can be configured with sampleSize property under
facets configuration node. Error rates are generally inversely proportional to √sample-size. So, to reduce error
rate by 1/2 sample size needs to increased 4 times.
Canonical example of statistical configuration would look like:
/oak:index/lucene-with-statistical-facets
+ facets
- secure = "statistical"
- sampleSize = 1500
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ tags
- facets = true
- propertyIndex = true
See query-engine regarding how to query to evaluate facets alongwith. Also check out some examples of queries and required index definitions for faceting in use case 5.
Score Explanation
@since Oak 1.3.12
Lucene supports explanation of scores which can be selected in a query using a virtual column oak:scoreExplanation.
e.g. select [oak:scoreExplanation], * from [nt:base] where foo='bar'
Note that showing explanation score is expensive. So, this feature should be used for debug purposes only.
Custom hooks
@since Oak 1.3.14
The following features is now deprecated:
In OSGi environment, implementations of IndexFieldProvider and FulltextQueryTermsProvider under
org.apache.jackrabbit.oak.plugins.index.lucene.spi (see javadoc here) are called during indexing
and querying as documented in javadocs.
Search by similar feature vectors
Oak Lucene index currently supports rep:similar queries via MoreLikeThis for text properties, this allows to search
for similar nodes by looking at texts.
This capability extends rep:similar support to feature vectors, typically used to represent binary content like images,
in order to search for similar nodes by looking at such vectors.
In order to index JCR properties holding vector values for similarity search, either in form of blobs or in form of texts,
the index definition should have a rule for each such property with the useInSimilarity parameter set to true.
As a result, after (re)indexing, each vector will be indexed so that an approximate nearest neighbour search is possible,
not requiring brute force nearest neighbour search over the entire set of indexed vectors.
By default, another property for feature vector similarity search, called similarityRerank, is set to true in order
to allow reranking of the top 15 results using brute force nearest neighbour.
Therefore, in a first iteration an approximate nearest neighbour search is performed to obtain all the possibly relevant
results (expecting high recall), then a brute force nearest neighbour over the top 15 search results is performed to
improve precision (see OAK-7824, OAK-7962,
OAK-8119).
As a further improvement for the accuracy of similarity search results if nodes having feature vectors also have properties
holding text values that can be used as keywords or tags that well describe the feature vector contents, the
similarityTags configuration can be set to true for such properties (see OAK-8118).
Similarity tag values that exceed the configured maxTagLength (default 100) are skipped during indexing.
This prevents unexpectedly long values from being indexed as similarity tags.
The limit can be changed by setting the maxTagLength property on the index definition,
or disabled entirely by setting it to -1. See OAK-12101.
Additionally, the maximum number of similarity tags indexed per document can be controlled
with the maxSimilarityTagsCount property (default 50). When the number of tags exceeds this limit,
only the first N tags (in order of appearance) are kept and subsequent tags are skipped.
Set to -1 to disable the limit entirely. See OAK-12117.
See also OAK-7575.
@since Oak 1.8.8
Design Considerations
Lucene index provides quite a few features to meet various query requirements. While defining the index definition do consider the following aspects
-
If query uses different path restrictions keeping other restrictions same then make use of
evaluatePathRestrictions -
If query performs sorting then have an explicit property definition for the property on which sorting is being performed and set
orderedto true for that property -
If the query is based on specific nodeType then define
indexRulesfor that nodeType -
Aim for a precise index configuration which indexes just the right amount of content based on your query requirement. An index which is precise would be smaller and would perform better.
-
Make use of nodetype to achieve a cohesive index. This would allow multiple queries to make use of same index and also evaluation of multiple property restrictions natively in Lucene
-
Non root indexes - If your query always perform search under certain paths then create index definition under those paths only. This might be helpful in multi tenant deployment where each tenant data is stored under specific repository path and all queries are made under those path.
In fact, it's recommended to use single index if all the properties being indexed are related. This would enable Lucene index to evaluate as much property restriction as possible natively (which is faster) and also save on storage cost incurred in storing the node path.
-
Use features when required - There are certain features provided by Lucene index which incur extra cost in terms of storage space when enabled. For example enabling
evaluatePathRestrictions,orderingetc. Enable such option only when you make use of those features and further enable them for only those properties. Soorderingshould be enabled only when sorting is being performed for those properties andevaluatePathRestrictionsshould only be enabled if you are going to specify path restrictions. -
Avoid overlapping index definition - Do not have overlapping index definition indexing same nodetype but having different
includedPathsandexcludedPaths. Index selection logic does not make use of theincludedPathsandexcludedPathsfor index selection. Index selection is done only on cost basis andqueryPaths. Having multiple definition for same type would cause ambiguity in index selection and may lead to unexpected results. Instead, have a single index definition for same type.
Following analogy might be helpful to people coming from RDBMS world. Treat your nodetype as Table in your DB and all the direct or relative properties as columns in that table. Various property definitions can then be considered as index for those columns.
Limits
The Apache Lucene version currently used in Oak has a limit of about 2^31 documents per index (this includes Lucene version 6). If a larger index is needed, please use Apache Solr, which doesn't have this limit.
Examples
Have a look at generating index definition for some tooling details which simplify generating index definition for given set of queries
A - Simple queries
In many cases the query is purely based on some specific property and is not restricted to any specific nodeType
SELECT
*
FROM [nt:base] AS s
WHERE ISDESCENDANTNODE([/content/public/platform])
AND s.code = 'DRAFT'
Following index definition would allow using Lucene index for above query
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
- evaluatePathRestrictions = true
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ code
- propertyIndex = true
- name = "code"
Above definition
- Indexes
codeproperty present on any node - Supports evaluation of path restriction i.e.
ISDESCENDANTNODE([/content/public/platform])viaevaluatePathRestrictions - Has a single indexRule for
nt:baseas queries do not specify any explicit nodeType restriction
Now you have another query like
SELECT
*
FROM [nt:base] AS s
WHERE
s.status = 'DONE'
Here we can either add another property to the above definition or create a new index definition altogether. By default, prefer to club such indexes together
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
- evaluatePathRestrictions = true
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ code
- propertyIndex = true
- name = "code"
+ status
- propertyIndex = true
- name = "status"
Taking another example. Lets say you perform a range query like
SELECT
[jcr:path],
[jcr:score],
*
FROM [nt:base] AS a
WHERE isdescendantnode(a, '/content')
AND [offTime] > CAST('2015-04-06T02:28:33.032-05:00' AS date)
This can also be clubbed in same index definition above
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
- evaluatePathRestrictions = true
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ nt:base
+ properties
- jcr:primaryType = "nt:unstructured"
+ code
- propertyIndex = true
- name = "code"
+ status
- propertyIndex = true
- name = "status"
+ offTime
- propertyIndex = true
- name = "offTime"
B - Queries for structured content
Queries in previous examples were based on mostly unstructured content where no nodeType restrictions were applied. However, in many cases the nodes being queried confirm to certain structure. For example, you have the following content
/content/dam/assets/december/banner.png
- jcr:primaryType = "app:Asset"
+ jcr:content
- jcr:primaryType = "app:AssetContent"
+ metadata
- dc:format = "image/png"
- status = "published"
- jcr:lastModified = "2009-10-9T21:52:31"
- app:tags = ["properties:orientation/landscape", "marketing:interest/product"]
- size = 450
- comment = "Image for december launch"
- jcr:title = "December Banner"
+ xmpMM:History
+ 1
- softwareAgent = "Adobe Photoshop"
- author = "David"
+ renditions (nt:folder)
+ original (nt:file)
+ jcr:content
- jcr:data = ...
Content like above is then queried in multiple ways. So lets take first query
UC1 - Find all assets which are having status as published
SELECT * FROM [app:Asset] AS a
WHERE a.[jcr:content/metadata/status] = 'published'
For this following index definition would have to be created
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ status
- propertyIndex = true
- name = "jcr:content/metadata/status"
Above index definition
- Indexes all nodes of type
app:Assetonly - Indexes relative property
jcr:content/metadata/statusfor all such nodes
UC2 - Find all assets which are having status as published sorted by last
modified date
SELECT * FROM [app:Asset] AS a
WHERE a.[jcr:content/metadata/status] = 'published'
ORDER BY a.[jcr:content/metadata/jcr:lastModified] DESC
To enable above query the index definition needs to be updated to following
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ status
- propertyIndex = true
- name = "jcr:content/metadata/status"
+ lastModified
- propertyIndex = true
- name = "jcr:content/metadata/jcr:lastModified"
- ordered = true
- type = Date
Above index definition
jcr:content/metadata/jcr:lastModifiedis marked asorderedenabling support order by evaluation i.e. sorting for such properties- Property type is set to
Date - Indexes both
statusandjcr:lastModified
UC3 - Find all assets where comment contains december
SELECT * FROM [app:Asset]
WHERE CONTAINS([jcr:content/metadata/comment], 'december')
To enable above query the index definition needs to be updated to following
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ comment
- name = "jcr:content/metadata/comment"
- analyzed = true
Above index definition
jcr:content/metadata/commentis marked asanalyzedenabling evaluation ofcontainsi.e. fulltext searchpropertyIndexis not enabled as this property is not going to be used to perform equality check
**UC4 - Find all assets which are created by David and refer to december **
SELECT * FROM [app:Asset]
WHERE CONTAINS(., 'december david')
Here we want to create a fulltext index for all assets. It would index all the
properties in app:Asset including all relative nodes. To enable that we need to
make use of aggregation
/oak:index/assetType
- jcr:primaryType = "oak:QueryIndexDefinition"
- compatVersion = 2
- type = "lucene"
- async = "async"
+ aggregates
+ app:Asset
+ include0
- path = "jcr:content"
+ include1
- path = "jcr:content/metadata"
+ include2
- path = "jcr:content/metadata/*"
+ include3
- path = "jcr:content/metadata/*/*"
+ include4
- path = "jcr:content/renditions"
+ include5
- path = "jcr:content/renditions/original"
+ nt:file
+ include0
- path = "jcr:content"
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ app:Asset
- includePropertyTypes = ["String", "Binary"]
+ properties
- jcr:primaryType = "nt:unstructured"
+ comment
- propertyIndex = true
- nodeScopeIndex = true
- name = "jcr:content/metadata/comment"
Above index definition
-
Only indexes
StringandBinaryproperties as part of fulltext index viaincludePropertyTypes -
Has
aggregatesdefined for various relative paths like jcr:content, jcr:content/metadata, jcr:content/renditions/original etc.With these rules properties like banner.png/metadata/comment, banner.png/metadata/xmpMM:History/1/author get indexed as part for fulltext index for banner.png node.
-
Inclusion of jcr:content/renditions/original would lead to aggregation of jcr:content/renditions/original/jcr:content/jcr:data property also as aggregation logic would apply rules for
nt:filewhile aggregating theoriginalnode -
Aggregation would include by default all properties which are part of
includePropertyTypes. However, if any property has an explicit property definition provided likecommentthennodeScopeIndexwould need to be set to true
Above definition would allow fulltext query to be performed. But we can do more.
Suppose you want to give more preference to those nodes where the fulltext term
is found in jcr:title compared to any other field. In such cases we can boost
such fields
+ indexRules
- jcr:primaryType = "nt:unstructured"
+ app:Asset
+ properties
- jcr:primaryType = "nt:unstructured"
+ comment
- propertyIndex = true
- nodeScopeIndex = true
- name = "jcr:content/metadata/comment"
+ title
- propertyIndex = true
- nodeScopeIndex = true
- name = "jcr:content/metadata/jcr:title"
- boost = 2.0
UC5 - Facets
Unconstrained queries for facets like
SELECT [rep:facet(title)] FROM [app:Asset]
or
/jcr:root//element(*, app:Asset)/(rep:facet(title))
or
SELECT [rep:facet(title)], [rep:facet(tags)] FROM [app:Asset]
or
/jcr:root//element(*, app:Asset)/(rep:facet(title) | rep:facet(tags))
would require an index on app:Asset containing all nodes of the type. That, in
turn, means that either the index needs to be a fulltext index or needs to be
indexing jcr:primaryType property. All the following definitions would work
for such a case:
+ /oak:index/index1
- ...
+ aggregates
+ app:Asset
+ include0
- path = "jcr:content"
+ indexRules
+ app:Asset
+ properties
+ title
- facets = true
+ tags
- facets = true
- propertyIndex = true
or
+ /oak:index/index2
- ...
+ indexRules
+ app:Asset
+ properties
+ title
- facets = true
- nodeScopeIndex = true
+ tags
- facets = true
- propertyIndex = true
or
+ /oak:index/index3
- ...
+ indexRules
+ app:Asset
+ properties
+ nodeType
- propertyIndex = true
- name = jcr:primaryType
+ title
- facets = true
+ tags
- facets = true
Another thing to note with facets is that facet counts are derived from lucene index. While not immediately obvious, that implies that any constraint on the query that do not get evaluated by the index are going to return incorrect facet counts as the other constraints would get filtered after collecting counts from the index.
So, following queries require correspondingly listed indexes:
SELECT rep:facet(title) FROM [app:Asset] WHERE ISDESCENDANTNODE('/some/path')
+ /oak:index/index2
- ...
- evaluatePathRestrictions = true
+ indexRules
+ app:Asset
+ properties
+ title
- facets = true
- propertyIndex = true
SELECT rep:facet(title) FROM [app:Asset] WHERE CONTAINS(., 'foo')
+ /oak:index/index2
- ...
+ indexRules
+ app:Asset
+ properties
+ title
- facets = true
- propertyIndex = true
- nodeScopeIndex = true
SELECT rep:facet(title) FROM [app:Asset] WHERE [title] IS NOT NULL
+ /oak:index/index2
- ...
+ indexRules
+ app:Asset
+ properties
+ title
- facets = true
- propertyIndex = true