

Pre-Extracting Text from Binaries
@since Oak 1.0.18, 1.2.3
Lucene indexing is performed in a single threaded mode. Extracting text from binaries is an expensive operation and slows down the indexing rate considerably. For incremental indexing this mostly works fine but if performing a reindex or creating the index for the first time after migration then it increases the indexing time considerably. To speed up such cases Oak supports pre extracting text from binaries to avoid extracting text at indexing time. This feature consist of 2 broad steps
- Extract and store the extracted text from binaries using oak-run tooling.
- Configure Oak runtime to use the extracted text at time of indexing via
PreExtractedTextProvider
For more details on this feature refer to OAK-2892
A - Oak Run Pre-Extraction Command
Oak run tool provides a tika command which supports traversing the repository and then extracting text from the
binary properties.
Step 1 - oak-run Setup
Download following jars
- oak-run 1.7.4 link
Refer to oak-run setup for details about connecting to different types of NodeStore. Example below assume a setup consisting of SegmentNodeStore and FileDataStore. Depending on setup use the appropriate connection options.
You can use current oak-run version to perform text extraction for older Oak setups i.e. its fine to use oak-run from 1.7.x branch to connect to Oak repositories from version 1.0.x or later. The oak-run tooling connects to the repository in read only mode and hence safe to use with older version.
The generated extracted text dir can then be used with older setup.
Of the following steps #2 i.e. generation of csv file scans the whole repository. Hence this step should be run when system is not in active use. Step #3 only requires access to BlobStore and hence can be run while Oak application is in use.
Step 2 - Generate the csv file
As the first step you would need to generate a csv file which would contain details about the binary property.
This file would be generated by using the tika command from oak-run. In this step oak-run would connect to
repository in read only mode.
To generate the csv file use the --generate action
java -jar oak-run.jar tika \
--fds-path /path/to/datastore \
/path/to/segmentstore --data-file oak-binary-stats.csv --generate
If connecting to S3 this command can take long time because checking binary id currently triggers download of the actual binary content which we do not require. To speed up here we can use the Fake DataStore support of oak-run
java -jar oak-run.jar tika \
--fake-ds-path=temp \
/path/to/segmentstore --data-file oak-binary-stats.csv --generate
This would generate a csv file with content like below
43844ed22d640a114134e5a25550244e8836c00c#28705,28705,"application/octet-stream",,"/content/activities/jcr:content/folderThumbnail/jcr:content"
43844ed22d640a114134e5a25550244e8836c00c#28705,28705,"application/octet-stream",,"/content/snowboarding/jcr:content/folderThumbnail/jcr:content"
...
By default it scans whole repository. If you need to restrict it to look up under certain path then specify the path via
--path option.
Step 3 - Perform the text extraction
Once the csv file is generated we need to perform the text extraction.
Currently extracted text files are stored as files per blob in a format which is same one used with FileDataStore
In addition to that it creates 2 files
- blobs_error.txt - File containing blobIds for which text extraction ended in error
- blobs_empty.txt - File containing blobIds for which no text was extracted
This phase is incremental i.e. if run multiple times and same --store-path is specified then it would avoid
extracting text from previously processed binaries.
There are 2 ways of doing this:
- Do text extraction using tika
- Use a suitable lucene index to get text extraction data from index itself which would have been generated earlier
Step 3.1 - Text extraction using tika
To do that we would need to download the tika-app jar from Tika downloads. You should be able to use 1.15 version with Oak 1.7.4 jar.
To perform the text extraction use the --extract action
java -cp oak-run.jar:tika-app-1.15.jar \
org.apache.jackrabbit.oak.run.Main tika \
--data-file binary-stats.csv \
--store-path ./store \
--fds-path /path/to/datastore extract
This command does not require access to NodeStore and only requires access to the BlobStore. So configure
the BlobStore which is in use like FileDataStore or S3DataStore. Above command would do text extraction
using multiple threads and store the extracted text in directory specified by --store-path.
Consequently, this can be run from a different machine (possibly more powerful to allow use of multiple cores) to speed up text extraction. One can also split the csv into multiple chunks and process them on different machines and then merge the stores later. Just ensure that at merge time blobs*.txt files are also merged
Note that we need to launch the command with -cp instead of -jar as we need to include classes outside of oak-run jar
like tika-app. Also ensure that oak-run comes before in classpath. This is required due to some old classes being packaged
in tika-app
3.2 - Populate text extraction store using already indexed data
@since Oak 1.9.3
This approach has some prerequisites to be consistent and useful:
Consistency between indexed data and csv generated in Step 2 above
NOTE: This is very important and not making sure of this can lead to incorrectly populating text extraction store.
Make sure that no useful binaries are added to the repository between the step that dumped indexed data and the one used for generating binary stats csv
Suitability of index used for populating extracted text store
Indexes which index binaries are obvious candidates to be consumed in this way. But there are few more constraints that the definition needs to adhere to:
- it should index binary on the same path where binary exists (binary must not be on a relative path)
- it should not index multiple binaries on the indexed path
- IOW, multiple non-relative property definitions don't match and index binaries
Example of usable index definitions
+ /oak:index/usableIndex1
...
+ indexRules
...
+ nt:resource
+ properties
...
+ binary
- name="jcr:data"
- nodeScopeIndex=true
+ /oak:index/usableIndex2
...
+ indexRules
...
+ nt:resource
+ properties
...
+ binary
- name="^[^\/]*$"
- isRegexp=true
- nodeScopeIndex=true
Examples of unusable index definitions
+ /oak:index/unUsableIndex1
...
+ indexRules
...
+ nt:file
+ properties
...
+ binary
- name="jcr:content/jcr:data"
- nodeScopeIndex=true
+ /oak:index/unUsableIndex2
...
+ aggregates
...
+ nt:file
...
+ include0
- path="jcr:content"
With those pre-requisites mentioned, let's dive into how to use this.
We'd first need to dump index data from a suitable index (say /oak:index/suitableIndexDef) using
dump index method at say /path/to/index/dump
Then use --populate action to populate extracted text store using a dump of usable indexed data. The command would
look something like:
java -jar oak-run.jar tika \
--data-file binary-stats.csv \
--store-path ./store \
--index-dir /path/to/index/dump/index-dumps/suitableIndexDef/data populate
This command doesn't need to connect to either node store or blob store, so we don't need to configure it in the execution.
This command would update blobs_empty.txt if indexed data for a given path is empty.
It would also update blobs_error.txt if indexed data for a given path has indexed special value TextExtractionError.
For other cases (multiple or none stored :fulltext fields for a given path) output of the command would report them as
errors but they won't be recorded in blobs_error.txt.
B - PreExtractedTextProvider
In this step we would configure Oak to make use of the pre extracted text for the indexing. Depending on how
indexing is being performed you would configure the PreExtractedTextProvider either in OSGi or in oak-run index command
Oak application
@since Oak 1.0.18, 1.2.3
For this look for OSGi config for Apache Jackrabbit Oak DataStore PreExtractedTextProvider
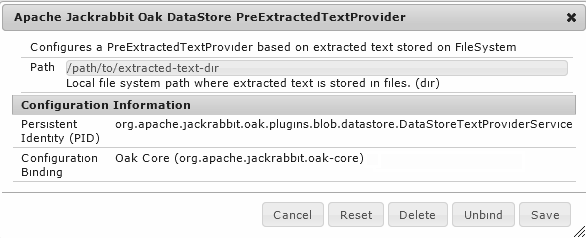
Once PreExtractedTextProvider is configured then upon reindexing Lucene
indexer would make use of it to check if text needs to be extracted or not. Check
TextExtractionStatsMBean for various statistics around text extraction and also
to validate if PreExtractedTextProvider is being used.
Oak Run Indexing
Configure the directory storing pre extracted text via --pre-extracted-text-dir option in index command.
See oak run indexing